.svg)
.svg)


はじめに
前回には、Interlocked operationを使用してコードのパフォーマンスを向上させる方法について学びました。今回は、他にもパフォーマンスを向上させるさまざまな方法について学びたいと思います。
メモリを事前に割り当ててパフォーマンスを向上させる
StringBuilderクラスは、C#で文字列操作を最適化するためによく使用されます。このクラスは文字列を動的に変更でき、大量の文字列操作が必要な場合は効率的に作業を実行できます。
ただし、StringBuilderに文字列を追加するときに、内部バッファ(メモリ空間)のサイズが十分でない場合は、StringBuilderに新しいメモリ空間を割り当てる必要があります。このプロセスでは追加の配列操作が必要になり、パフォーマンスが低下する可能性があります。
そのため、文字列操作作業が多い場合、あらかじめ十分な大きさのメモリ空間を割り当てておくことで、このような性能低下を防ぐことができます。この方法の利点は、StringBuilderが必要とするメモリスペースを事前に知っていれば、不要なメモリの再割り当てと配列作業を減らすことができることです。
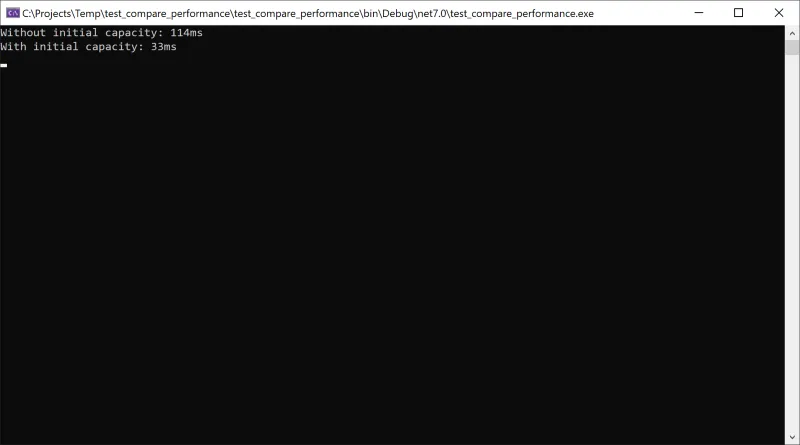
これはこれの簡単なサンプルコードです。メモリを再割り当てされて処理するコードが発生する性能低下の大きさは非常に大きくはありませんが、繰り返しが多く起こる場合には適用してみる必要があります。赤い背景を持つコード部分がメモリを事前に割り当てられるようにする部分です。
using System;using System.Diagnostics;using System.Text;class Program{static void Main(string[] args){const int iterationCount = 1000000; // テスト反復回数const string appendText = "This is a test."; // StringBuilderに追加する文字列// 初期割り当てなしのStringBuilderテストvar sw = Stopwatch.StartNew();var sb1 = new StringBuilder();for (int i = 0; i < iterationCount; i++){sb1.Append(appendText);}sw.Stop();Console.WriteLine($"Without initial capacity: {sw.ElapsedMilliseconds}ms");// 初期割り当て付きのStringBuilderテストsw.Restart();var sb2 = new StringBuilder(iterationCount * appendText.Length);for (int i = 0; i < iterationCount; i++){sb2.Append(appendText);}sw.Stop();Console.WriteLine($"With initial capacity: {sw.ElapsedMilliseconds}ms");Console.ReadLine();}}
以下のスクリーンショットは実行結果です。
Word 単位でまとめてパフォーマンスを上げる
配列などの長いデータを比較または処理するときは、Word単位で束ねて使用することが想定パフォーマンスです。コンピュータは、メモリを複数のビットで構成される「ワード(word)」という単位で読み書きする方法を使用します。このワードのサイズはコンピュータアーキテクチャによって異なり、通常は32ビットまたは64ビットを多用します。
1つのワードを読み書きするとき、CPUは1回の操作でワード内のすべてのビットを同時に処理できます。つまり、ワード単位でデータを処理すると、1つの操作でより多くのデータを処理できるため、より高速なパフォーマンスが得られます。ただし、ワード単位でデータを処理するには、データがワードのサイズに合わせてソートされている必要があります。そのため、バイト配列をワードサイズの「int」配列に変換するプロセスが必要です。このように変換すると、ワード単位でより多くのデータを一度に処理できます。一方、データをバイト単位で処理すると、ワード単位で処理する場合よりも多くの操作が必要になります。
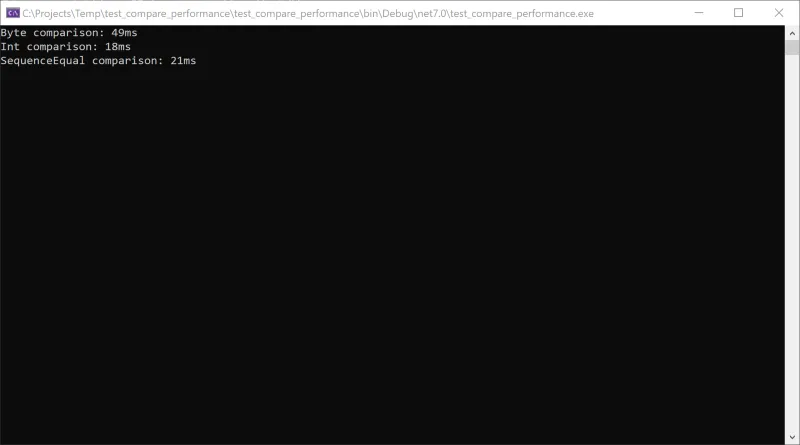
using System;using System.Diagnostics;using System.Linq;class Program{static void Main(string[] args){const int length = 10000000; // 配列の長さconst byte fillValue = 0x1; // 配列埋める値// 2つの配列の初期化byte[] arr1 = new byte[length];byte[] arr2 = new byte[length];for (int i = 0; i < length; i++){arr1[i] = fillValue;arr2[i] = fillValue;}// byteで比較var sw = Stopwatch.StartNew();for (int i = 0; i < length; i++){if (arr1[i] != arr2[i]){Console.WriteLine("Arrays are not equal");}}sw.Stop();Console.WriteLine($"Byte comparison: {sw.ElapsedMilliseconds}ms");// intで比較int[] arr1Int = new int[length / 4];int[] arr2Int = new int[length / 4];Buffer.BlockCopy(arr1, 0, arr1Int, 0, length);Buffer.BlockCopy(arr2, 0, arr2Int, 0, length);sw.Restart();for (int i = 0; i < length / 4; i++){if (arr1Int[i] != arr2Int[i]){Console.WriteLine("Arrays are not equal");}}sw.Stop();Console.WriteLine($"Int comparison: {sw.ElapsedMilliseconds}ms");// SequenceEqualsw.Restart();if (!arr1.SequenceEqual(arr2)){Console.WriteLine("Arrays are not equal");}sw.Stop();Console.WriteLine($"SequenceEqual comparison: {sw.ElapsedMilliseconds}ms");Console.ReadLine();}}
以下のスクリーンショットは実行結果です。SequenceEqual() が Word 単位で束ねて実行するよりも少しパフォーマンスが低下しますが、コードが簡潔でデータの種類を気にする必要がないという利点があります。
コンピュータのパフォーマンスを向上させる別の方法としては、SIMD(Single Instruction Multiple Data)を使用することがあります。SIMDとは、単一の命令を使用して複数のデータに対して同時に演算を実行する方法を意味します。この方式は、ベクトル化演算が必要な科学的計算やグラフィック、デジタル信号処理など、さまざまな分野で活用されます。
SIMDは、特定のデータ型の配列やリストなどに対して同じ操作を実行する必要がある場合に最も効率的です。 たとえば、2 つのベクトルのすべての要素を加算したり、配列のすべての要素を特定の定数で乗算したりする場合に SIMD を使用すると、パフォーマンスを大幅に向上させることができます。
メモリは順次アクセスすれば性能が高くなる
今回は、2次元配列への順次アプローチと列優先(Column major)アプローチとの違いを比較してみましょう。
行優先方式(Row major)は、メモリに連続して格納されたデータを順次読み出す。 これは、CPUがデータを効率的にインポートできるようにします。なぜなら、CPUがメモリからデータをインポートするときに1つの値だけをインポートするのではなく、「ブロック」単位でインポートするからです。 これは「プリフェッチ(prefetch)」と呼ばれ、CPUは後で必要になると予想されるメモリ位置のデータを事前に取得します。したがって、毎回データをインポートする動作を省略してパフォーマンスを引き上げることができるようになるのです。
一方、列優先方式(Column major)は連続していないメモリ位置に近づくため、CPUはプリフェッチを効率的に実行できません。これは毎回異なるアドレスからデータを取得する必要があるため、より多くの時間がかかります。
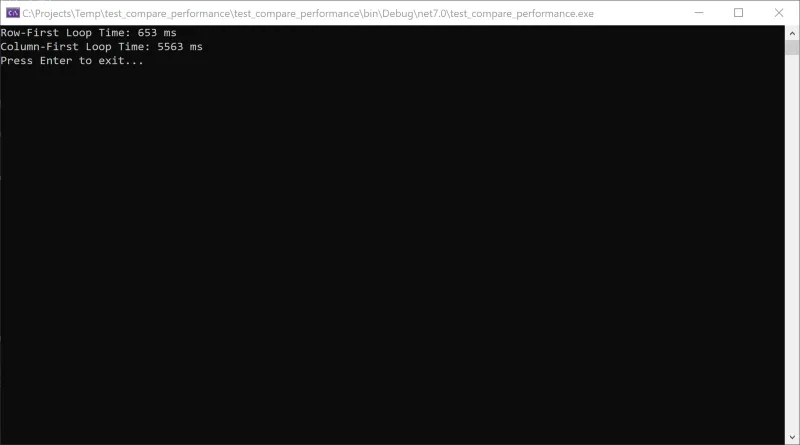
using System;using System.Diagnostics;class Program{static void Main(string[] args){int size = 10000;int[][] datas = new int[size][];for (int i = 0; i < size; i++){datas[i] = new int[size];for (int j = 0; j < size; j++){datas[i][j] = i * j;}}var stopwatch = new Stopwatch();// First Loop (Row-First)stopwatch.Start();int count1 = 0;for (int i = 0; i < datas.Length; i++){for (int j = 0; j < datas.Length; j++){if (datas[i][j] > 0){count1++;}}}stopwatch.Stop();Console.WriteLine($"Row-First Loop Time: {stopwatch.ElapsedMilliseconds} ms");// Second Loop (Column-First)stopwatch.Restart();int count2 = 0;for (int i = 0; i < datas.Length; i++){for (int j = 0; j < datas.Length; j++){if (datas[j][i] > 0){count2++;}}}stopwatch.Stop();Console.WriteLine($"Column-First Loop Time: {stopwatch.ElapsedMilliseconds} ms");Console.ReadLine();}}
以下のスクリーンショットは実行結果です。違いがかなりあることが確認できます。
ハッシュマップを活用した性能向上
今回は、レガシーコードで発見された二重反復文を介して資料を探索するコードのパフォーマンス改善について見ていきます。実務のコードがかなり長く、他の作業に関するコードによって理解しにくいことがあるので、擬似コードレベルで説明を進めます。
繰り返し検索操作が必要な場合は、ハッシュマップなどの高速検索パフォーマンスを提供するデータ構造を使用すると、大きなパフォーマンス向上が得られます。今回のケースがまさにその状況に該当します 以下のレガシーコードは、関数名のリストとメソッドのリストを繰り返しながら、一致する関数を見つけることを行います。このコードは二重反復文を使用するため、時間の複雑さはO(n2)です。
void SearchFunctionNameInMethods(){List<string> functionNames = new List<string>() { "Function1", "Function2", "Function3" };MethodInfo[] methods = ...;foreach (string functionName in functionNames){foreach (MethodInfo method in methods){if (method.Name == functionName){Console.WriteLine("Method {0} is found.", functionName);}}}}
このコードを最適化するために、関数名のリストをHashSetに変更しました。HashSetは内部的にハッシュテーブルを使用してデータを格納するため、検索操作の時間の複雑さはO(1)です。したがって、以下の最適化されたコードはメソッドのリストだけを繰り返しながら関数名が HashSet に含まれていることを確認するので、時間の複雑さはO(n)に大幅に改善されました。
さらに、繰り返しステートメントが単純になり、コードの読みやすさも向上したという利点もあります。
void SearchFunctionNameInMethods(){HashSet<string> functionNames = new HashSet<string>() { "Function1", "Function2", "Function3" };MethodInfo[] methods = ...;foreach (MethodInfo method in methods){if (functionNames.Contains(method.Name)){Console.WriteLine("Method {0} is found.", method.Name);}}}
スレッドアイドリングを避ける
スレッドのアイドリング(busy-waiting)やループの使用はかなり頻繁に見えるプログラミングパターンです。特定のタスクを実行した後、一定時間待機し(Sleep()メソッドを使用)、その後再びタスクを開始する形です。これらのアプローチはしばしば非効率的であり、CPUリソースを不必要に使用することが多い。
これを改善する1つの方法は、Guarded Suspensionパターンを使用することです。このパターンでは、スレッドはタスクを実行する必要がある場合にのみ目覚め、そうでない場合は待機状態に留まります。 レガシーコードではデータを集めておき、定期的に処理するコードがこうしてSleep()を利用した場合でした。 このコードをGuarded suspension patternを適用してバッファに一定サイズのデータが集められたら、スレッドをウェイクアップ形式に置き換えることでパフォーマンスを向上させることができます。
public class DataProcessor{public DataProcessor(){_thread = new Thread(ProcessBuffer);_thread.IsBackground = true;_thread.Start();}public void AddData(string log){lock (_lock){_buffer.Add(log);}}private void ProcessBuffer(){while (true){Thread.Sleep(10);lock (_lock){if (_buffer.Count >= BufferSizeLimit){// データ処理_buffer.Clear();}}}}}
public class DataProcessor{public DataProcessor(){thread = new Thread(() => {while (true){lock (_lock){Monitor.Wait(_lock);// データ処理}}});thread.IsBackground = true;thread.Start();}public void AddData(string log){lock (_lock){buffer.Add(log);if (buffer.Length > BUFFER_SIZE_LIMIT) Monitor.Pulse(_lock);}}}
しかし、今回の場合はどちらが必ずしも性能に有利であるとは言えません。状況に合わせて選択しなければなりません。それぞれの特徴を見てみましょう。レガシーコードはThread.Sleep()を使用して、スレッドが一定時間ごとに起動し、データが十分に蓄積されていることを確認します。この方法はデータが即座に処理されるため、反応性が良いです。ただし、Sleep 時間中に他のスレッドが実行される可能性があるため、コンテキスト切り替えがより頻繁に発生する可能性があります。
Guarded Suspension パターンを使用する 2 番目のコードは、モニターを使用してデータを処理するスレッドが必要な場合にのみ起動するように設計されています。データが十分に蓄積されていない場合、スレッドはMonitor.Wait()を介してブロック状態になります。データが十分に積み重なると、Monitor.Pulse() によって目覚め、データを処理します。これはCPU使用率を削減するのに有効であり、不要なコンテキストスイッチングを最小限に抑えます。ただし、反応性の観点からは、データが十分に蓄積されるのを待つ必要があるため、遅延が発生する可能性があります。
したがって、2つの方法の間の選択はユースケースによって異なります。 実際のパフォーマンスの違いは、使用するシステムや環境、ワークロードなど、さまざまな要因によって異なります。
乾いたタオルを絞る除算性能を向上
一般に、コンピュータでは、ビットシフト演算が除算演算よりも高速である。 これは、ビットシフト演算が単純なレジスタ演算であるため、除算演算はCPUで複雑な演算を実行する必要があるためです。
「value / 12」演算は以下のようなコードに変更できます。 '>>' は右にビットを移動する演算子であり、 'value>>2' は value を 4 で割ったものと同じ結果を提供します。その後、この結果を3で割るので、全体の操作は元の 'value / 12'と同じ結果を提供します。
int result = (value >> 2) / 3;
しかし、この方法にはいくつかの欠点があります。
① これらの最適化は、読みやすさを阻害し、コードを複雑にする可能性があります。
② コンパイラはすでにこの種の最適化を実行することがよくあります。したがって、プログラマが直接これらの最適化を行うことはしばしば不要である。
③ この最適化は除算演算を完全に除去することはできず、依然として '(value>>2)/3' から 3 に分割する演算が必要です.
したがって、実際のコーディングでは、直接的な除算操作を使用する方が良いです。読みやすさを維持し、コンパイラが自動的に実行できる最適化を実行するようにします。
しかし、これらの最適化手法が有効な状況もあります。たとえば、特定のプラットフォームでコンパイラの最適化が制限されている場合、または特定の操作で極端なパフォーマンス向上が必要な場合は、これらの最適化手法を適用できます。この場合、この最適化を適用する前後のパフォーマンスを測定して実際の効果を確認することが重要です。
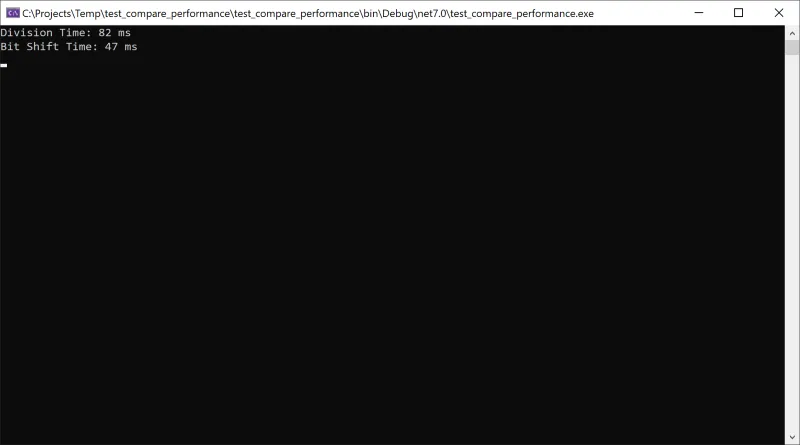
using System;using System.Diagnostics;class Program{static void Main(string[] args){Stopwatch sw = new Stopwatch();// Divisionsw.Start();for (int i = 0; i < 10000000; i++){int result = i / 2;}sw.Stop();Console.WriteLine($"Division Time: {sw.ElapsedMilliseconds} ms");sw.Reset();// Bit Shiftsw.Start();for (int i = 0; i < 10000000; i++){int result = i >> 1; // Same as dividing by 2}sw.Stop();Console.WriteLine($"Bit Shift Time: {sw.ElapsedMilliseconds} ms");Console.ReadLine();}}
以下のスクリーンショットは実行結果です。
おわりに
今回のポストでは、最後に続き、もう少し多様な状況での性能改善について見てきました。プロジェクトを進行する途中にメモしたものだから、やや不足した面が多いです。イーグルの反応を見て機会になれば、他の状況についても扱うようにします。
これらの方法はすべて状況によって適用されるべき方法が異なり、時には互いに矛盾することがあります。したがって、どの方法が最も効果的であるかを判断するためには、システムの要件と特性を正確に理解し、さまざまな方法を適用し、その効果を直接確認することが重要です。
私のポストが皆様のパフォーマンス最適化にお役に立てたらと思います。




